Nếu bạn đang tìm kiếm một chiếc laptop mới, việc xác định mức giá hợp lý là một thách thức không nhỏ. Thay vì phải “săn lùng” thông tin qua hàng ngàn trang web và cửa hàng trực tiếp mất rất nhiều thời gian, một chút kiến thức về Python và hồi quy tuyến tính có thể giúp bạn đưa ra quyết định thông minh hơn. Bài viết này sẽ hướng dẫn bạn cách xây dựng một công cụ dự đoán giá laptop, giúp bạn nắm bắt giá trị thực của sản phẩm và tránh mua “hớ”.
Tại Sao Cần Xây Dựng Công Cụ Dự Đoán Giá Laptop?
Thị trường laptop hiện nay vô cùng đa dạng với hàng ngàn mẫu mã từ nhiều thương hiệu khác nhau, mỗi chiếc lại có cấu hình và mức giá riêng biệt. Việc tự mình so sánh và đánh giá để tìm ra mức giá hợp lý cho một chiếc laptop với cấu hình mong muốn gần như là bất khả thi đối với người dùng thông thường. Bạn có thể dành hàng giờ, thậm chí hàng ngày để tìm kiếm nhưng vẫn cảm thấy bối rối và không chắc chắn về quyết định của mình.
Chúng tôi tin rằng không ai muốn phải chi trả quá nhiều cho một sản phẩm công nghệ. Chính vì vậy, ý tưởng về một chương trình có thể nhập các thông số kỹ thuật như dung lượng RAM, độ phân giải màn hình hay tốc độ CPU và nhận về một mức giá dự đoán hợp lý là cực kỳ hữu ích. Với kinh nghiệm về thống kê, đặc biệt là hồi quy tuyến tính, việc xây dựng một mô hình như vậy bằng Python trở nên khả thi và hiệu quả. Python, với sự đơn giản và các thư viện mạnh mẽ, đã trở thành ngôn ngữ phổ biến trong phân tích dữ liệu, giúp cả những người không chuyên về khoa học máy tính cũng có thể tiếp cận.
 laptop Lenovo Yoga Slim 9i Gen 10 đang mở đặt trên bàn làm việc
laptop Lenovo Yoga Slim 9i Gen 10 đang mở đặt trên bàn làm việc
Chuẩn Bị Bộ Công Cụ Thống Kê Python
Để xây dựng mô hình dự đoán giá laptop, chúng ta cần một bộ công cụ Python chuyên biệt cho phân tích dữ liệu và thống kê. Mặc dù nhiều hệ điều hành đã tích hợp Python, việc sử dụng môi trường riêng biệt như Mamba (hoặc VirtualEnv) là cần thiết để tránh xung đột hệ thống và quản lý thư viện hiệu quả hơn.
Các thư viện chính mà chúng ta sẽ sử dụng bao gồm:
- NumPy: Đây là thư viện cơ bản và phổ biến nhất cho các phép toán số học, đặc biệt là các tính toán thống kê và đại số tuyến tính vốn là nền tảng của các mô hình học máy.
- Pandas: Thư viện này cho phép bạn làm việc với dữ liệu dạng bảng (Data Frame) một cách mạnh mẽ và linh hoạt, tương tự như làm việc với cơ sở dữ liệu quan hệ hoặc bảng tính Excel. Pandas sẽ giúp chúng ta nhập, xem và thao tác dữ liệu dễ dàng.
- Seaborn: Được xây dựng dựa trên Matplotlib, Seaborn là thư viện tuyệt vời để trực quan hóa dữ liệu thống kê. Chúng ta sẽ sử dụng nó để tạo biểu đồ histogram, scatterplot và biểu diễn hồi quy tuyến tính, giúp dễ dàng nhận diện các phân phối và mối quan hệ trong dữ liệu.
- Pingouin: Đây là một thư viện thống kê mạnh mẽ giúp thực hiện nhiều kiểm định thống kê khác nhau mà không cần phải nhớ các công thức phức tạp. Pingouin sẽ là công cụ chính để xây dựng mô hình hồi quy tuyến tính đa biến của giá bán lẻ dựa trên các thuộc tính của laptop.
![]() Logo Python Seaborn trên nền biểu đồ trực quan hóa dữ liệu với các thanh, đường cong và chấm điểm
Logo Python Seaborn trên nền biểu đồ trực quan hóa dữ liệu với các thanh, đường cong và chấm điểm
Ngoài ra, Jupyter Notebook là một môi trường tương tác thân thiện giúp bạn chạy các lệnh Python, xem kết quả ngay lập tức và lưu trữ toàn bộ quá trình làm việc. Bạn có thể cài đặt Windows Subsystem for Linux (WSL) trên Windows để có môi trường Unix-like, sau đó cài đặt Mamba và tạo môi trường Python riêng. Để kích hoạt môi trường đã tạo, bạn chỉ cần gõ lệnh mamba activate stats trong terminal Linux.
Thu Thập Dữ Liệu Laptop
Để xây dựng một mô hình hồi quy chính xác, việc có một tập dữ liệu đầy đủ và chất lượng là vô cùng quan trọng. Thay vì tự mình thu thập dữ liệu từ các cửa hàng trực tuyến, một quá trình tốn kém thời gian và công sức để làm sạch dữ liệu, chúng ta sẽ tận dụng một kho dữ liệu có sẵn.
Nền tảng Kaggle cung cấp một tập dữ liệu về giá laptop cùng với các thông số kỹ thuật phần cứng như tốc độ CPU, dung lượng RAM, bộ nhớ lưu trữ chính và phụ, độ phân giải màn hình (chiều rộng và chiều cao). Tập dữ liệu này có sẵn tại Kaggle. Giá trong tập dữ liệu ban đầu được tính bằng Euro, tuy nhiên, tỷ giá hối đoái giữa Euro và Đô la Mỹ vào tháng 7 năm 2025 khá tương đồng, nên chúng ta có thể xem xét giá này mà không cần chuyển đổi phức tạp.
Xây Dựng Mô Hình Hồi Quy Dự Đoán Giá
Sau khi đã chuẩn bị môi trường và có dữ liệu, giờ là lúc xây dựng mô hình.
Đầu tiên, chúng ta cần import các thư viện đã chuẩn bị:
import numpy as np
import pandas as pd
import seaborn as sns
%matplotlib inline
import pingouin as pgCác dòng này sẽ import NumPy, Pandas, Seaborn và Pingouin, đồng thời rút gọn tên gọi thành “np, pd, sns, pg” để dễ sử dụng. Dòng %matplotlib inline dùng trong Jupyter Notebook để hiển thị biểu đồ trực tiếp trong notebook.
Tiếp theo, chúng ta sẽ nhập dữ liệu từ file CSV bằng Pandas:
laptops = pd.read_csv("data/laptop_prices.csv")Lệnh này sẽ tạo ra một DataFrame của Pandas. Chúng ta có thể xem cấu trúc dữ liệu bằng phương thức head():
laptops.head()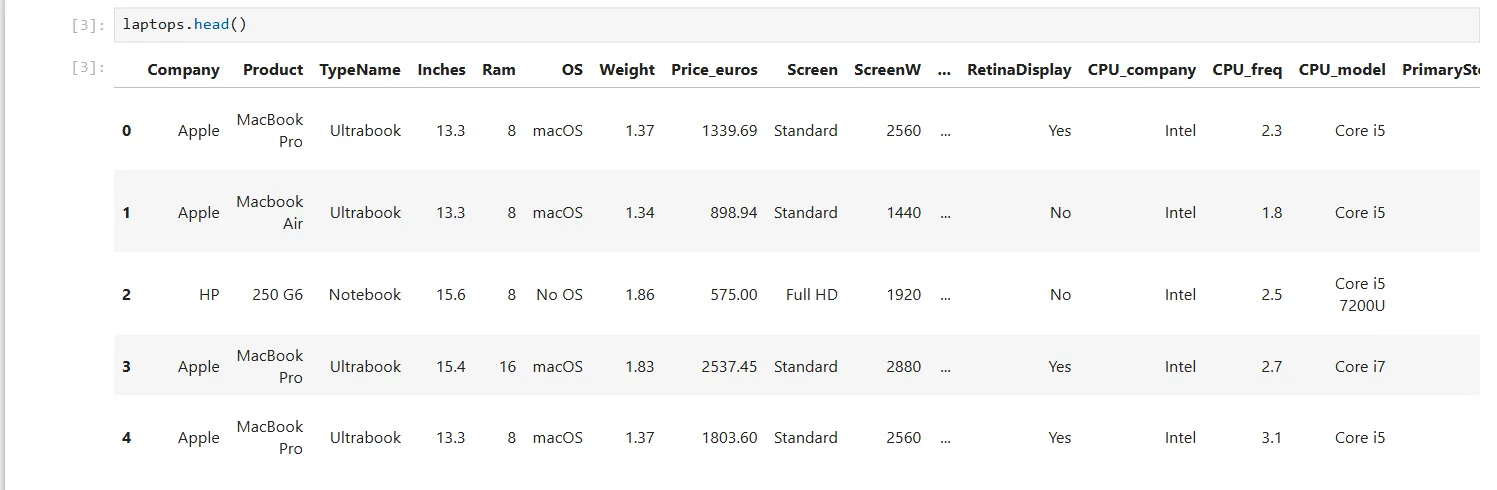 Kết quả từ phương thức head() của Pandas trong Jupyter Notebook, hiển thị 5 dòng dữ liệu đầu tiên của tập dữ liệu laptop
Kết quả từ phương thức head() của Pandas trong Jupyter Notebook, hiển thị 5 dòng dữ liệu đầu tiên của tập dữ liệu laptop
Để có cái nhìn tổng quan hơn, chúng ta có thể xem các thống kê mô tả cơ bản của tất cả các cột số bằng phương thức describe():
laptops.describe()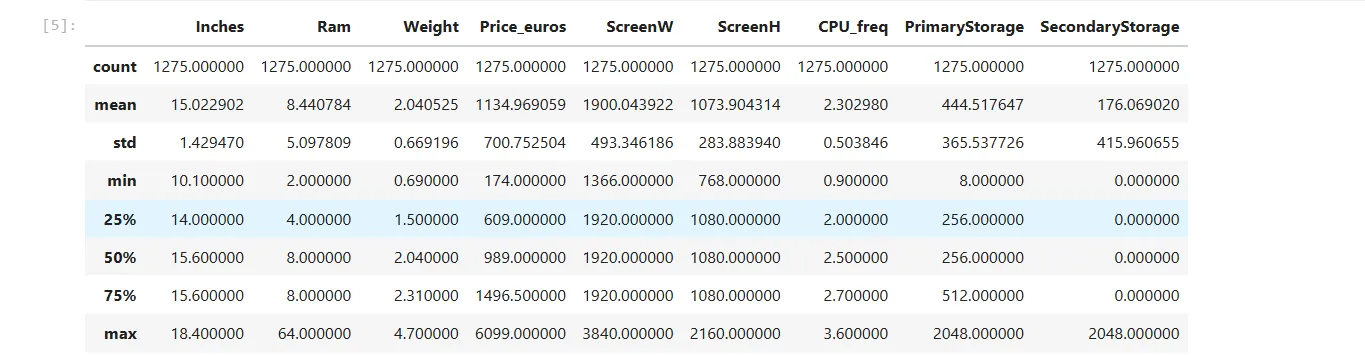 Thống kê mô tả (describe()) của các cột dữ liệu số trong tập dữ liệu laptop, hiển thị giá trị trung bình, độ lệch chuẩn, min, max
Thống kê mô tả (describe()) của các cột dữ liệu số trong tập dữ liệu laptop, hiển thị giá trị trung bình, độ lệch chuẩn, min, max
Kết quả này sẽ hiển thị giá trị trung bình (mean), trung vị (median), độ lệch chuẩn (standard deviation), giá trị tối thiểu (min), phân vị thứ 25 (lower quartile), phân vị thứ 75 (upper quartile) và giá trị tối đa (max) của mỗi cột.
Để hiểu rõ hơn về phân phối giá, chúng ta có thể trực quan hóa dữ liệu bằng biểu đồ histogram của Seaborn:
sns.displot(x='Price_euros',data=laptops)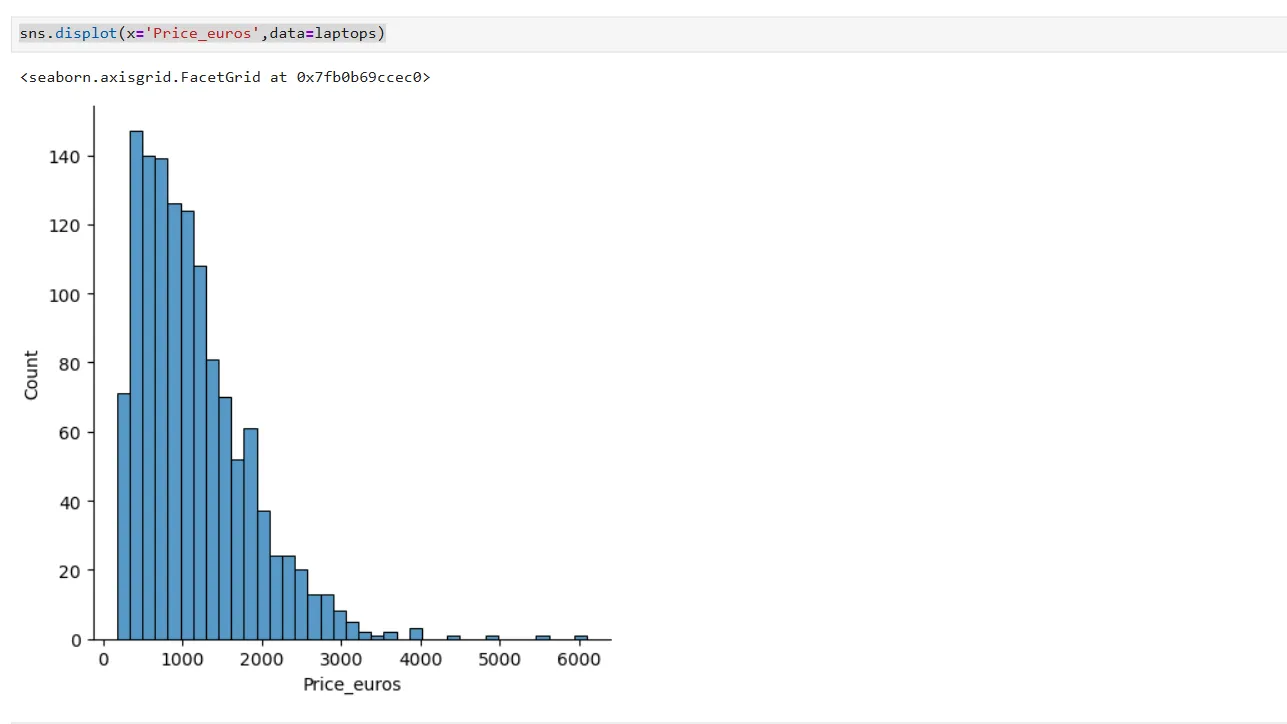 Biểu đồ phân phối giá laptop (Price_euros) được tạo bằng Seaborn trong Jupyter Notebook, cho thấy sự lệch phải của dữ liệu
Biểu đồ phân phối giá laptop (Price_euros) được tạo bằng Seaborn trong Jupyter Notebook, cho thấy sự lệch phải của dữ liệu
Biểu đồ này cho thấy phân phối giá có đuôi lệch rõ rệt về phía phải, nghĩa là có một số laptop có giá cao hơn đáng kể so với mặt bằng chung.
Mô hình chúng ta sẽ xây dựng có dạng hồi quy tuyến tính đa biến, tương tự như công thức sau:
giá = a(tốc độ CPU) + b(RAM) + c(kích thước màn hình) + …
Trong đó, a, b, c là các hệ số (coefficients) được xác định bởi quá trình hồi quy. Thay vì chỉ phù hợp một đường thẳng trên biểu đồ scatterplot như hồi quy tuyến tính đơn giản, chúng ta sẽ “khớp” một mặt phẳng (hoặc siêu mặt phẳng trong trường hợp có nhiều hơn ba chiều) với dữ liệu.
Để thực hiện hồi quy giá (Price_euros) theo các thuộc tính của laptop như kích thước màn hình (Inches), RAM, cân nặng (Weight), độ rộng màn hình (ScreenW), độ cao màn hình (ScreenH), tần số CPU (CPU_freq), bộ nhớ chính (PrimaryStorage) và bộ nhớ phụ (SecondaryStorage), chúng ta sử dụng hàm linear_regression của Pingouin:
pg.linear_regression(laptops[['Inches','Ram','Weight','ScreenW','ScreenH','CPU_freq','PrimaryStorage','SecondaryStorage']],laptops['Price_euros'],relimp=True)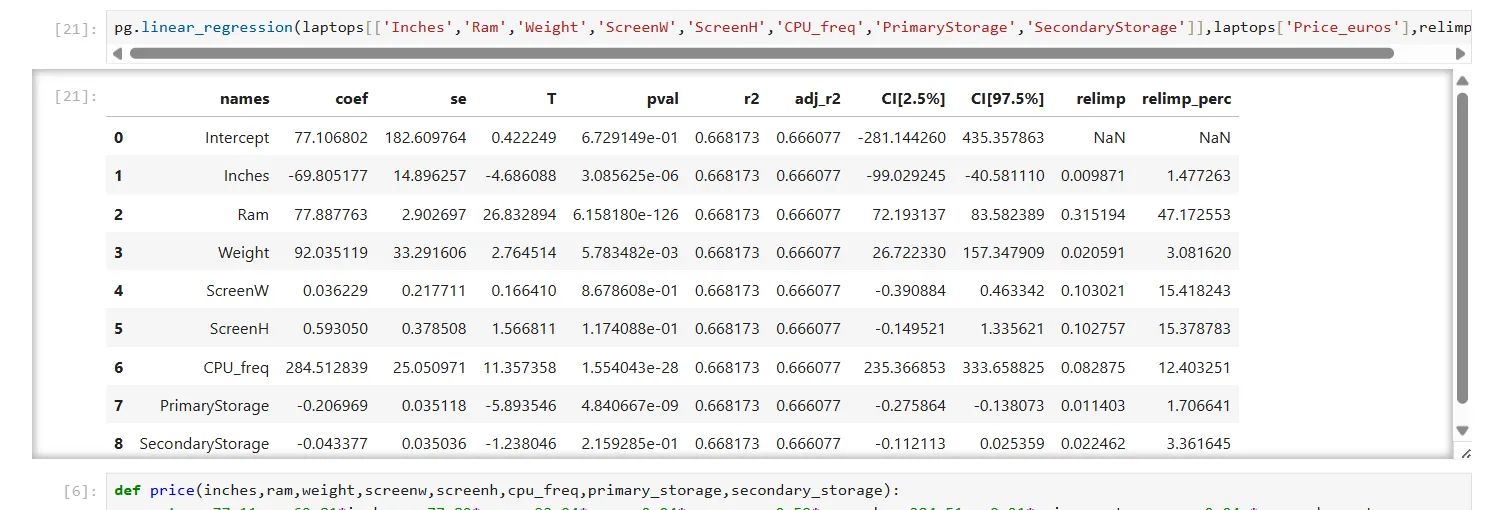 Kết quả mô hình hồi quy tuyến tính đa biến (linear_regression) dự đoán giá laptop, hiển thị các hệ số và R-squared
Kết quả mô hình hồi quy tuyến tính đa biến (linear_regression) dự đoán giá laptop, hiển thị các hệ số và R-squared
Kết quả này cung cấp các hệ số cho phương trình hồi quy. Cột ngoài cùng bên trái hiển thị các hệ số, trong khi cột ngoài cùng bên phải cho biết mức độ đóng góp tương đối của mỗi biến vào việc dự đoán giá. Từ bảng kết quả, RAM là yếu tố dự đoán giá quan trọng nhất. Chỉ số r2 (hệ số xác định R-squared) khoảng 0.66, cho thấy mô hình có độ phù hợp khá tốt với dữ liệu.
Với các hệ số đã dự đoán, chúng ta có thể xây dựng một hàm để ước tính giá dựa trên các thông số kỹ thuật:
def price(inches,ram,weight,screenw,screenh,cpu_freq,primary_storage,secondary_storage):
return 77.11 + -69.81*inches + 77.89*ram + 92.04*ram + 0.04*screenw + 0.59*screenh + 284.51 - 0.21*primary_storage + -0.04 * secondary_storage(Lưu ý: Dòng thứ hai cần được thụt lề trong mã Python thực tế.)
Giá Laptop Có Thực Sự Khác Biệt Giữa Các Thương Hiệu?
Mô hình hồi quy tuyến tính ở trên chỉ xem xét các thông số kỹ thuật. Tuy nhiên, một câu hỏi khác đặt ra là liệu giá có thực sự khác biệt đáng kể giữa các thương hiệu laptop hay không. Chúng ta có thể sử dụng phân tích phương sai (ANOVA) để xác định xem sự khác biệt giữa các thương hiệu có ý nghĩa thống kê hay không. Do dữ liệu giá bị lệch (như đã thấy trong biểu đồ histogram), một kiểm định phi tham số sẽ chính xác hơn. Pingouin cung cấp kiểm định Kruskal-Wallis phù hợp cho trường hợp này.
Kiểm định này sẽ kiểm tra giả thuyết null rằng không có mối quan hệ giữa giá và thương hiệu:
pg.kruskal(data=laptops,dv='Price_euros',between='Company').round(2) Kết quả kiểm định Kruskal-Wallis trong Jupyter Notebook, phân tích sự khác biệt về giá laptop giữa các thương hiệu sản xuất
Kết quả kiểm định Kruskal-Wallis trong Jupyter Notebook, phân tích sự khác biệt về giá laptop giữa các thương hiệu sản xuất
Giá trị p (p-value) là 0, điều này có nghĩa là sự khác biệt về giá giữa các thương hiệu là có ý nghĩa thống kê rất lớn. Việc làm tròn giá trị p giúp dễ dàng nhận thấy điều này. Với p-value nhỏ hơn 0.05 (ngưỡng thông thường), chúng ta có thể bác bỏ giả thuyết null và kết luận rằng thương hiệu là một yếu tố dự đoán giá quan trọng.
Bằng cách sử dụng Python và các thư viện thống kê mạnh mẽ, chúng ta đã có thể xây dựng một mô hình dự đoán giá laptop dựa trên cấu hình và một công cụ để xác định mức độ ảnh hưởng của thương hiệu đến giá. Điều này không chỉ giúp bạn đưa ra quyết định mua sắm thông minh hơn mà còn cho thấy sức mạnh của khoa học dữ liệu trong việc biến những vấn đề phức tạp thành những giải pháp đơn giản chỉ với vài dòng mã.
Với những kiến thức và công cụ này, bạn hoàn toàn có thể tự mình phân tích và đưa ra những quyết định sáng suốt hơn khi lựa chọn laptop. Hãy thử áp dụng và chia sẻ những khám phá của bạn trong phần bình luận!